The Past and Present of LLM RAG (Retrieval-Augmented Generation)
/ 4 min read /
Table of Contents 目录
What is LLM RAG?
LLM: Large Language Model
RAG: Retrieval-Augmented Generation
Retrieval-Augmented Generation for large language models is a technique that optimizes the output of large language models by incorporating external knowledge bases. The core idea is to retrieve relevant information from an external database and feed it into the generation module along with the user’s query, producing responses that are more accurate, relevant, and up-to-date.
Background
RAG was actually introduced back in 2020. A Facebook paper, Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, first proposed the concept. The problem this paper aimed to solve is simple: how to make language models generate using external knowledge. Normally, the knowledge of a pretrained model is stored in its parameters, which means the model doesn’t know about anything outside its training data (e.g., search data, domain-specific knowledge). The old approach was to fine-tune the pretrained model whenever new knowledge came along. But that had two problems:
- You’d have to fine-tune every time there was new knowledge.
- Training models is very expensive.
So RAG came along. It leverages the ability of pretrained models to learn and understand new knowledge by injecting that new knowledge into the prompt, producing more reliable responses. Let’s wrap up by looking at the current issues with LLMs.

RAG System Components and How It Works
A minimal RAG system consists of just three parts:
- A language model
- A collection of external knowledge the model needs (stored as vectors)
- The external knowledge required for the current scenario
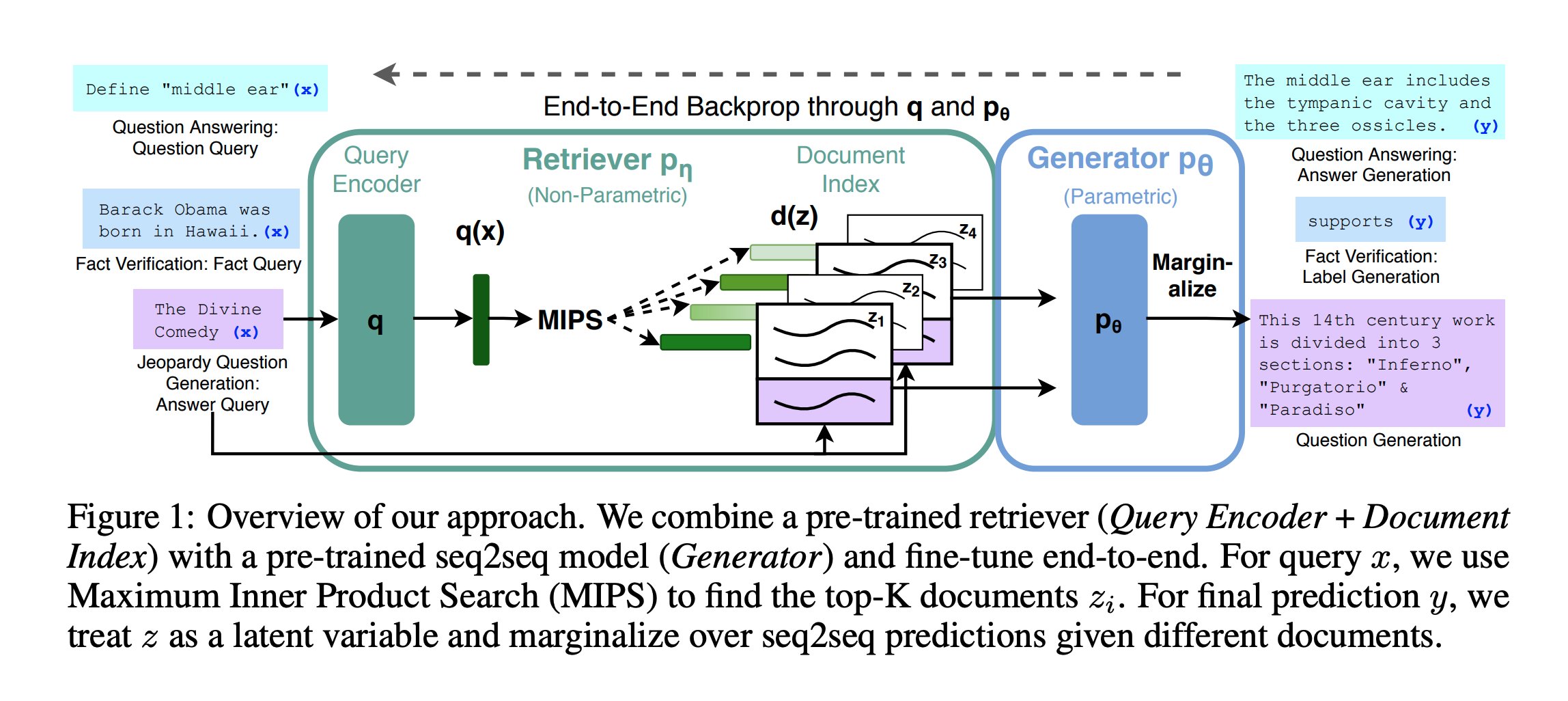
The diagram above shows the components of an RAG system; here’s a quick explanation:
- Input query: The left side shows three different types of input queries:
- QA task: e.g., “Define ‘middle ear’”
- Fact verification: e.g., “Barack Obama was born in Hawaii”
- Jeopardy (reverse QA) question generation: e.g., “Divine Comedy”, AI generates a corresponding question
- Query Encoder: Encodes the input query into a vector representation q(x).
- Retriever pη: A non-parametric model that uses Maximum Inner Product Search (MIPS) to find documents relevant to the query from the document index.
- Document index d(z): Stores pre-encoded document vectors (z1, z2, z3, z4, etc.).
- Generator pθ: A parametric model that generates the final answer based on retrieved documents.
- Marginalize: Marginalizes over the seq2seq predictions from different documents to produce the final output.
- Output: Generates different outputs depending on the task type:
- QA: generates an answer, e.g., “The middle ear includes the tympanic cavity and three ossicles”
- Fact verification: generates a label, e.g., “Supports”
- Question generation: generates a question, e.g., “This 14th-century work is divided into three parts: ‘Inferno’, ‘Purgatorio’, and ‘Paradiso’”
- End-to-end backpropagation: The entire process is trained end-to-end via q and pθ to optimize performance.
- Method overview: This approach combines a pretrained retriever (query encoder + document index) with a pretrained seq2seq model (generator) and fine-tunes them end-to-end. For a query x, MIPS is used to find the top-K relevant documents zi. When making the final prediction y, z is treated as a latent variable and the seq2seq predictions over different documents are marginalized.
The advantage of this approach is that it can handle multiple NLP (Natural Language Processing) tasks and improve performance by combining retrieval and generation. With end-to-end training, the system learns to better coordinate retrieval and generation, leading to more accurate results.
The workflow of an RAG system is shown below:

Let’s take a quick, high-level look at the full process of building an RAG chat bot:
- Load data
In real projects, data sources can come in many formats, e.g., PDFs, code, existing databases, cloud databases, etc. We need to load all this data, typically using a vector database.
- Chunk data
Models have a limited context window, so we need to split the data into chunks. But because data sources vary and natural language has its own characteristics, choosing a chunking function and setting its parameters is actually very tricky. Ideally, we want each document chunk to be semantically coherent and independent of the others.
- Embed
This is the process of converting text into vectors, then using similarity matching to retrieve the data we want. It also solves the problem of content being too large.
- Retrieve data
Convert the query into a vector, then search against the vectors in the vector database to retrieve the desired results.
You can also use a traditional relational database + Elasticsearch for data retrieval.
- Augment the prompt
Actually, everything above is done to augment the prompt. We combine the retrieved information with the user’s question to create an augmented prompt, which is then submitted to the LLM.
- Generate
Pass the augmented prompt to the generator model to produce the answer.
Summary
There are two intuitive ways to understand what RAG does:
- RAG gives the LLM an external boost.
- The LLM acts as a thinking brain, while RAG provides the relevant knowledge. RAG retrieves a set of knowledge, and the LLM then thinks, organizes, and generates the result.
References
- How devv builds an efficient RAG system: https://x.com/forrestzh_/status/1731478506465636749
- RAG Introduction: https://github.com/datawhalechina/llm-universe/blob/main/docs/C1/2.%E6%A3%80%E7%B4%A2%E5%A2%9E%E5%BC%BA%E7%94%9F%E6%88%90%20RAG%20%E7%AE%80%E4%BB%8B.md