Harness Engineering: Leveraging Codex in an Agent-First World
/ 15 min read /
Table of Contents 目录
Here is the https://openai.com/index/harness-engineering/ blog post body in a complete Chinese-to-English translation, a high-quality article that changes the rules of the software engineering game.
Original title: Harness Engineering: Tapping into Codex in an Agent-First World
Author: Ryan Lopopolo, Published: February 11, 2026
Translator: 🥥 Coconut Translation Browser Plugin
For the past five months, our team has been running an experiment: building and shipping a beta version of an internal software product with 0 lines of human-written code.
The product now has internal daily users and external alpha testers. It ships, deploys, breaks, and gets fixed normally. The difference is that every single line of code — including application logic, tests, CI configuration, documentation, observability configuration, and internal tooling — was written by Codex. By our estimates, we completed this work in about one-tenth the time it would have taken humans.
Humans at the Helm, Agents at the Wheel
We deliberately chose this constraint to force ourselves to build the systems necessary to increase engineering velocity by orders of magnitude. We had only weeks to deliver a project that ended up at a million lines of code. To do it, we needed to understand what changes when the primary job of a software engineering team shifts from writing code to designing environments, clarifying intent, and building feedback loops where Codex agents can work reliably.
This article shares what we’ve learned building a brand-new product with a team of agents (what went wrong, what compounded), and how to maximize our only scarce resource: human time and attention.
We Started from an Empty Git Repository
The first commit into that empty repo was in late August 2025.
The initial scaffolding — repo structure, CI configuration, formatting rules, package manager setup, and application framework — was generated by Codex CLI using GPT-5, bootstrapped with a small set of existing templates. Even the AGENTS.md file, which initially instructed the agents on how to work in the repo, was itself written by Codex.
No pre-existing human code anchored the system. From the very beginning, this repo was shaped by agents.
Five months later, the repo contains roughly a million lines of code spanning application logic, infrastructure, tooling, documentation, and internal developer utilities. Over that period, a small team of just three engineers drove Codex to open and merge about 1500 pull requests (PRs). That’s an average of 3.5 PRs per engineer per day, and surprisingly, throughput has increased as the team grew to seven engineers today. Importantly, this wasn’t output for output’s sake: the product is used by hundreds of internal users, including deep daily users.
Throughout development, humans never directly contributed any code. That became the team’s core philosophy: no human-written code.
Redefining the Engineer’s Role
The absence of manual coding introduced a different kind of engineering work, focusing on systems, scaffolding, and leverage.
Early progress was slower than we expected — not because Codex lacked capability, but because environments were poorly defined. Agents lacked the tools, abstractions, and internal structures they needed to make progress toward high-level goals. Our engineering team’s primary job became empowering agents to do useful work.
In practice, that meant working depth-first: breaking larger goals into smaller building blocks (design, code, review, test, etc.), prompting agents to build those blocks, and using them to unlock more complex tasks. When something broke, the fix was almost never “try again.” Since the only way to make progress was to get Codex to do the work, human engineers would always step in and ask, “What capability is missing, and how can we make that capability both visible and enforceable to the agent?”
Humans interacted with the system almost entirely through prompts: an engineer describes a task, runs the agent, and lets it open a pull request. To drive the PR to completion, we instruct Codex to review its own changes locally, request additional specific agents for review locally and in the cloud, respond to any human or agent feedback, and loop until all agent reviewers are satisfied (effectively a Ralph Wiggum loop). Codex directly uses our standard development tools (gh, local scripts, and in-repo skills) to gather context, no human copy-pasting into a CLI.
Humans might review the pull request, but it wasn’t mandatory. Over time, we pushed nearly all review work to an agent-to-agent pattern.
Making the Application More Readable
As code throughput increased, the bottleneck became human QA capacity. With the fixed constraint of human time and attention, we worked to give agents more leverage by making things like the application UI, logs, and application metrics directly visible to Codex.
For example, we made the application launchable per git worktree, so Codex could boot and drive an instance for each change. We also wired Chrome DevTools Protocol into the agent runtime and created skills for handling DOM snapshots, screenshots, and navigation. This allowed Codex to reproduce bugs, verify fixes, and reason about UI behavior directly.
 (Caption: Codex uses Chrome DevTools MCP to drive the application to verify its work.)
(Caption: Codex uses Chrome DevTools MCP to drive the application to verify its work.)
We did the same for observability tooling. Logs, metrics, and traces were exposed to Codex through a local observability stack, ephemeral per worktree. Codex works on a fully isolated version of the application (including its logs and metrics), which gets torn down when the task is done. Agents could query logs with LogQL and metrics with PromQL. With this context, prompts like “ensure the service starts within 800ms” or “no span exceeds 2 seconds across these four critical user journeys” became executable.
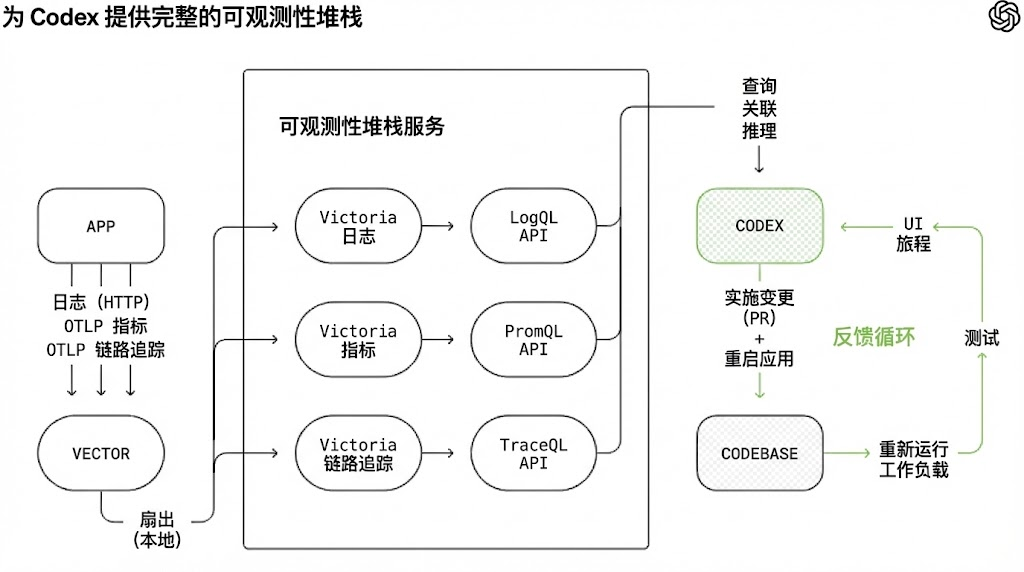 (Caption: Giving Codex a full observability stack in local development.)
(Caption: Giving Codex a full observability stack in local development.)
We often saw a single Codex run work continuously on a single task for six hours or more (often while humans slept).
We Made Repo Knowledge the System of Record
Context management is one of the biggest challenges in keeping agents efficient on large, complex tasks. One of the earliest lessons was simple: give Codex a map, not a 1000-page manual.
We tried the “one giant AGENTS.md” approach. It failed predictably:
-
Context is scarce. A huge instruction file crowds out space for the task, code, and relevant documentation, leading agents to either miss critical constraints or optimize for the wrong ones.
-
Too much guidance becomes no guidance. When everything is “important,” nothing is important. Agents fall into local pattern matching and can’t navigate intentionally.
-
It rots immediately. Giant manuals become graveyards of outdated rules. Agents can’t tell what’s real, humans stop maintaining it, and the file silently becomes a tempting nuisance.
-
Hard to verify. A single large file isn’t amenable to mechanical checks (coverage, freshness, ownership, cross-links), so drift is inevitable.
So instead of treating AGENTS.md as an encyclopedia, we treated it as a directory.
The repo’s knowledge lives in a structured docs/ directory, treated as the system of record. A short AGENTS.md (~100 lines) is injected into context, functioning primarily as a map with pointers to deeper sources of truth elsewhere.
1 AGENTS.md2 ARCHITECTURE.md3 docs/4 ├── design-docs/5 │ ├── index.md6 │ ├── core-beliefs.md7 │ └── ...8 ├── exec-plans/9 │ ├── active/10 │ ├── completed/11 │ └── tech-debt-tracker.md12 ├── generated/13 │ └── db-schema.md14 ├── product-specs/15 │ ├── index.md16 │ ├── new-user-onboarding.md17 │ └── ...18 ├── references/19 │ ├── design-system-reference-llms.txt20 │ ├── nixpacks-llms.txt21 │ ├── uv-llms.txt22 │ └── ...23 ├── DESIGN.md24 ├── FRONTEND.md25 ├── PLANS.md26 ├── PRODUCT_SENSE.md27 ├── QUALITY_SCORE.md28 ├── RELIABILITY.md29 └── SECURITY.md(Repo knowledge layout.)
Design docs were categorized and indexed, with validation status and a set of core beliefs defining agent-first operational principles. Architecture docs provided a top-level map of domains and package layering. Quality docs scored each product domain and architecture layer, tracking gaps over time.
Plans were treated as first-class artifacts. Ephemeral lightweight plans were used for small changes, while complex work was recorded in execution plans with progress logs and decisions, committed to the repo. Active plans, completed plans, and known tech debt were all versioned and colocated, allowing agents to operate without relying on external context.
This enabled progressive disclosure: agents start with a small, stable entry point and are taught where to look next, avoiding overwhelm upfront.
We enforced this mechanically. Dedicated linters and CI tasks verified that the knowledge base was up-to-date, correctly cross-linked, and structurally sound. A periodically running “document gardener” agent scanned for stale or outdated docs that no longer reflected real code behavior and opened fix-up PRs.
Agent-Readability Was the Goal
As the codebase evolved, so did Codex’s design decision framework.
Because the repo was entirely agent-generated, it was optimized first and foremost for Codex readability. Just as a team works to make code navigable for a new engineer, we human engineers aimed to let agents infer the full business domain directly from the repo itself.
From an agent’s perspective, anything it cannot access in context at runtime effectively doesn’t exist. Knowledge in Google Docs, chat threads, or people’s heads is inaccessible to the system. Local, versioned artifacts — code, markdown, schemas, executable plans — are all it can see.
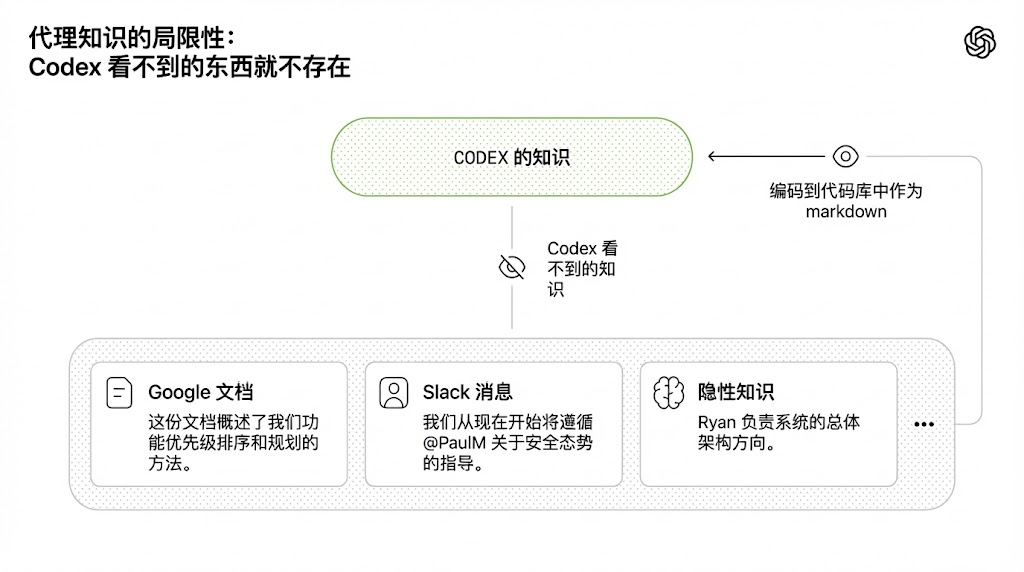 (Caption: The limits of agent knowledge: what Codex can’t see doesn’t exist.)
(Caption: The limits of agent knowledge: what Codex can’t see doesn’t exist.)
We learned that over time, we needed to push more and more context into the repo. If a Slack discussion aligned the team on a certain architectural pattern, that knowledge was invisible to agents — just as it would be for a new hire joining three months later — and therefore unreadable.
Giving Codex more context meant organizing and exposing the right information for agents to reason over, rather than overwhelming them with ad-hoc instructions. Just as you would onboard a new teammate with product principles, engineering standards, and team culture (including emoji preferences), providing that information to agents produces more consistent output.
This framing clarified many trade-offs. We gravitated toward dependencies and abstractions that could be fully internalized and reasoned about in the repo. Technologies often described as “boring” tended to be easier for agents to model because of their composability, API stability, and broad presence in training data. In some cases, it was cheaper to let the agent reimplement part of a feature than to work around opaque upstream behavior in a public library. For example, instead of pulling in a generic p-limit style package, we implemented our own concurrent map helper: it was tightly integrated with our OpenTelemetry instrumentation, had 100% test coverage, and behaved exactly as expected at runtime.
Turning more parts of the system into a form that agents could directly inspect, verify, and modify increased leverage — not just for Codex but also for other agents working on the codebase, like Aardvark.
Enforcing Architecture & Taste
Documentation alone cannot keep a fully agent-generated codebase coherent. By enforcing invariants without micro-managing implementation details, we let agents ship fast without breaking the foundation. For example, we required Codex to parse data shapes at boundaries, but didn’t prescribe how (the model seemed to like Zod, but we didn’t specify that particular library).
Agents work best in environments with strict boundaries and predictable structures, so we built the application around a rigorous architectural model. Each business domain was divided into a fixed set of layers, with strictly validated dependency direction and a limited set of allowed edges. These constraints were mechanically enforced via custom linters (generated by Codex, of course!) and structural tests.
The diagram below illustrates the rule: within each business domain (e.g., application settings), code could only depend “forward” through a fixed set of layers (Types → Config → Repo → Service → Runtime → UI). Cross-cutting concerns (auth, connectors, telemetry, feature flags) entered through a single explicit interface: Providers. Any other dependency was forbidden and mechanically prevented.
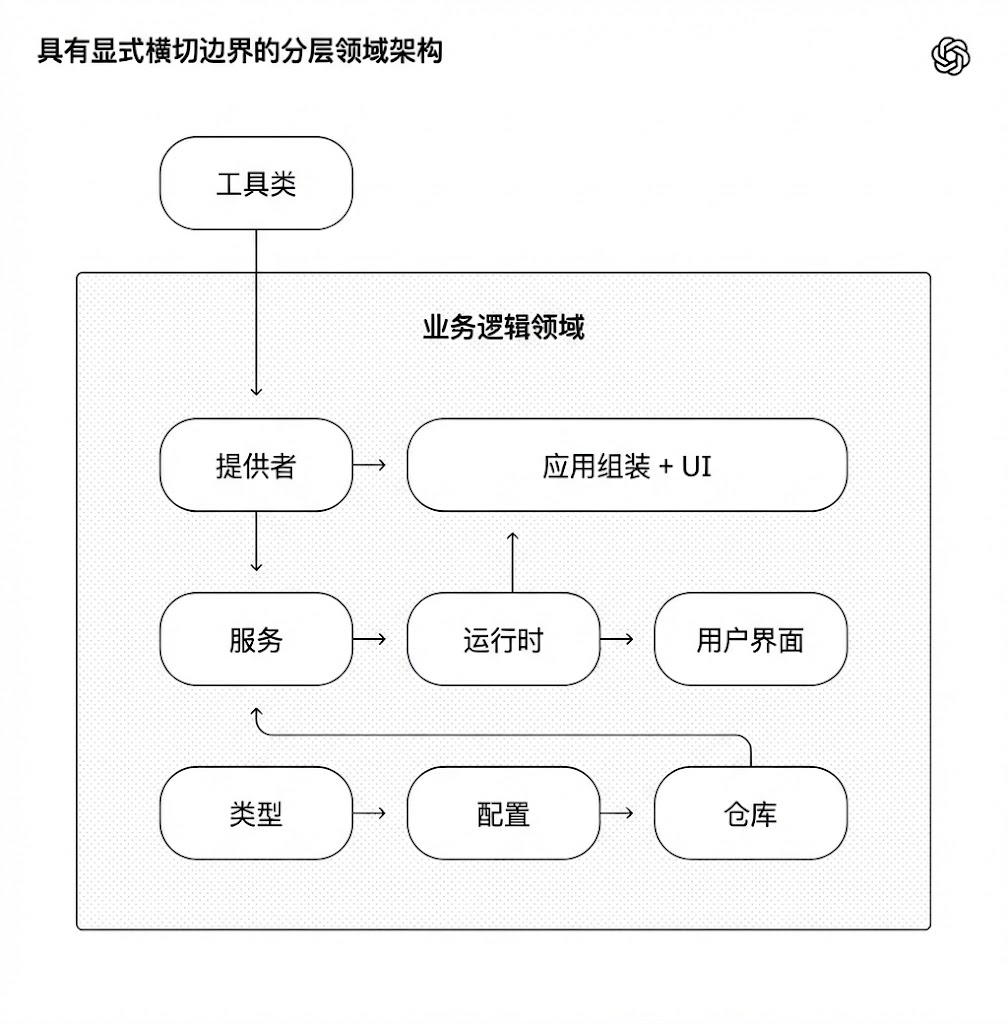 (Caption: Layered domain architecture with explicit cross-cutting boundaries.)
(Caption: Layered domain architecture with explicit cross-cutting boundaries.)
This is the kind of architecture you usually defer until you have hundreds of engineers. For coding agents, it was an early prerequisite: the constraint that made speed possible without rot or architectural drift.
In practice, we enforced these rules via custom linters and structural tests, plus a small set of “taste invariants.” For example, we statically enforced structured logging, naming conventions for schemas and types, file size limits, and platform-specific reliability requirements. Because the linters were custom, we wrote error messages that inject remediation instructions into agent context.
In human-first workflows, these rules can feel pedantic or restrictive. From an agent’s perspective, they become multipliers: once coded, they apply everywhere simultaneously.
At the same time, we explicitly distinguished where constraints matter and where they don’t. This is similar to leading a large engineering platform org: enforce boundaries at the center, allow autonomy locally. You care deeply about boundaries, correctness, and reproducibility. Within those boundaries, you allow teams (or agents) great freedom in expressing solutions.
Generated code does not always match human stylistic preferences, and that’s okay. As long as the output is correct, maintainable, and readable for future agent runs, it meets the bar.
Human taste feeds back into the system continuously. Review comments, refactoring PRs, and user-facing errors are captured as documentation updates or directly encoded into tooling. When documentation isn’t enough, we elevate rules into code.
Throughput Changed the Merge Philosophy
As Codex throughput increased, many conventional engineering practices became counterproductive.
The repo maintained minimally blocking merge requirements at runtime. PRs were short-lived. Test flakiness was typically dealt with via subsequent runs, not blocking progress indefinitely. In a system where agent throughput far exceeds human attention, fixes are cheap and waiting is expensive.
In a low-throughput environment, this would be irresponsible. Here, it was often the right tradeoff.
What “Agent-Generated” Really Means
When we say the codebase was generated by Codex agents, we mean everything in the codebase.
Agents produced:
-
Product code and tests
-
CI configuration and release tooling
-
Internal developer tools
-
Documentation and design history
-
Evaluation harnesses
-
Review comments and replies
-
Scripts to manage the repo itself
-
Production dashboard definition files
Humans stayed in the loop, but worked at a different level of abstraction than before. We prioritized work, translated user feedback into acceptance criteria, and validated outcomes. When an agent got stuck, we treated it as a signal: identify what was missing (tools, guardrails, documentation), feed it back into the repo, always by letting Codex write the fix itself.
Agents directly used our standard development tools. They pulled review feedback, made inline replies, pushed updates, and often squashed and merged their own PRs.
Increasing Levels of Autonomy
As more development loops were directly encoded into the system (testing, validation, review, feedback handling, and recovery), the repo recently crossed a meaningful threshold: Codex could drive a new feature end-to-end.
Given a single prompt, the agent can now:
-
Verify the current state of the codebase
-
Reproduce a reported bug
-
Record a video demo of the failure
-
Implement a fix
-
Verify the fix by driving the application
-
Record a second video demo of the solution
-
Open a pull request
-
Respond to agent and human feedback
-
Detect and fix build failures
-
Only escalate to a human when judgment is needed
-
Merge the change
This behavior relies heavily on the specific structure and tooling of this repo, and shouldn’t be assumed to generalize without similar investment (at least not yet).
Entropy and Garbage Collection
Full agent autonomy also introduced new problems. Codex replicates existing patterns in the repo, even uneven or suboptimal ones. Over time, this inevitably leads to drift.
Initially, humans solved this manually. Our team used to have “AI slop cleanup” on Fridays (20% of the week). Unsurprisingly, this didn’t scale.
Instead, we started to encode what we called “golden rules” directly into the repo and established a regular cleanup process. These rules are opinionated mechanical rules designed to keep the codebase readable and consistent for future agent runs. For example:
(1) We prefer shared utility packages over ad-hoc helper functions to keep invariants centralized;
(2) We don’t do “YOLO-style” data probing; we validate boundaries or rely on typed SDKs, lest agents accidentally build on guessed data shapes. On a fixed cadence, we have a set of background Codex tasks that scan for deviations, update quality scores, and open targeted refactoring PRs. Most of these can be reviewed and auto-merged in under a minute.
This acts like garbage collection. Tech debt is like a high-interest loan: continuously paying it off in small increments is almost always better than letting it compound and resolving it in painful bursts. Human taste is captured once and then enforced on every line of code, continuously. It also lets us catch and fix bad patterns daily, preventing them from spreading across the codebase for days or weeks.
What We Still Need to Learn
So far, this approach has worked well for internal releases and adoption at OpenAI. Building real products for real users helped anchor our investment in reality and guide us toward long-term maintainability.
What we don’t yet know is how architectural consistency evolves over years in a fully agent-generated system. We are still learning where human judgment adds the most leverage, and how to encode that judgment so it compounds. We also don’t know how this system will evolve as models become more capable over time.
What is clear: building software still requires discipline, but that discipline now lives more in scaffolding, outside the code. The tools, abstractions, and feedback loops that keep a codebase coherent are increasingly important.
Our hardest challenges now center on designing environments, feedback loops, and control systems to help agents achieve our goals: building and maintaining complex, reliable software at scale.
As agents like Codex take on a larger share of the software lifecycle, these questions will only become more important. We hope sharing some early lessons helps you think about where to invest your attention so you can focus on building things.